
順序ロジスティック回帰分析の基本:データの形式、前提条件、分析結果の解釈
前回は二項ロジスティック回帰分析についてまとめましたが、今回は順序ロジスティック回帰分析を取り上げます。数式や細かい理論は省き、どういうデータの何を知りたいときに順序ロジスティック回帰分析を行うのか、前提条件は何か、分析結果をどのように解釈するのか、などについて解説していきます。
統計解析サービス
統計解析のご依頼・ご相談に研究者が対応しています。解析方法や論文での書き方が分からないという方でも、研究者に直接相談できるのでご安心ください。料金は2万2000円〜

どういうデータ?
順序ロジスティック回帰分析は、目的変数が順序尺度のときに行います。順序尺度なので、正規性や等分散性などの前提条件は求められません。
説明変数は連続データ(数量データ)である必要があるので、順序尺度の場合はデータを連続データとして扱い、名義尺度の場合はダミー変数(0・1)に置き換えます。順序尺度を連続データとして扱うのは統計学的には問題がありますが、実際にはよく行われています。それが許容されるかどうかは分野によりますので、事前に調べておくと良いでしょう。
何を知りたい?
下の表は、ある電化製品についてユーザーの満足度をアンケート調査した結果の例です(『アンケート調査の計画と解析』のデータ表を改変)。「デザイン」や「機能性」、「総合評価」などの各項目について、1:非常に不満、2:不満、3:やや不満、4:中間、5:やや満足、6:満足:7:非常に満足、という7段階の評定尺度で集計しています。
| 回答者 | デザイン | 機能性 | 操作性 | 携帯性 | 持続性 | 総合評価 |
|---|---|---|---|---|---|---|
| 1 | 7 | 5 | 3 | 3 | 6 | 6 |
| 2 | 7 | 3 | 5 | 3 | 7 | 7 |
| 3 | 4 | 2 | 3 | 2 | 4 | 3 |
| 4 | 2 | 1 | 1 | 1 | 3 | 2 |
| 5 | 2 | 3 | 4 | 1 | 1 | 2 |
| 6 | 4 | 4 | 2 | 6 | 4 | 4 |
| 7 | 1 | 4 | 4 | 2 | 6 | 3 |
| 8 | 2 | 3 | 4 | 1 | 1 | 1 |
| 9 | 5 | 3 | 6 | 6 | 3 | 4 |
| 10 | 4 | 3 | 4 | 5 | 3 | 6 |
| 11 | 4 | 4 | 3 | 6 | 3 | 2 |
| 12 | 3 | 4 | 1 | 2 | 4 | 3 |
| 13 | 6 | 5 | 4 | 5 | 5 | 5 |
| 14 | 5 | 5 | 2 | 4 | 4 | 4 |
| 15 | 1 | 3 | 4 | 2 | 1 | 2 |
| 16 | 3 | 7 | 4 | 4 | 5 | 5 |
| 17 | 1 | 4 | 2 | 3 | 2 | 1 |
| 18 | 4 | 1 | 3 | 7 | 4 | 4 |
| 19 | 3 | 6 | 7 | 6 | 3 | 5 |
| 20 | 3 | 1 | 3 | 1 | 3 | 1 |
ここで、「総合評価」に最も強く影響している要素は何かを調べたいとき、総合評価を目的変数、それ以外を説明変数として、順序ロジスティック回帰分析を行います。
結果の解釈
上の表のデータを、統計ソフトJMPを使って順序ロジスティック回帰分析した結果を示します。
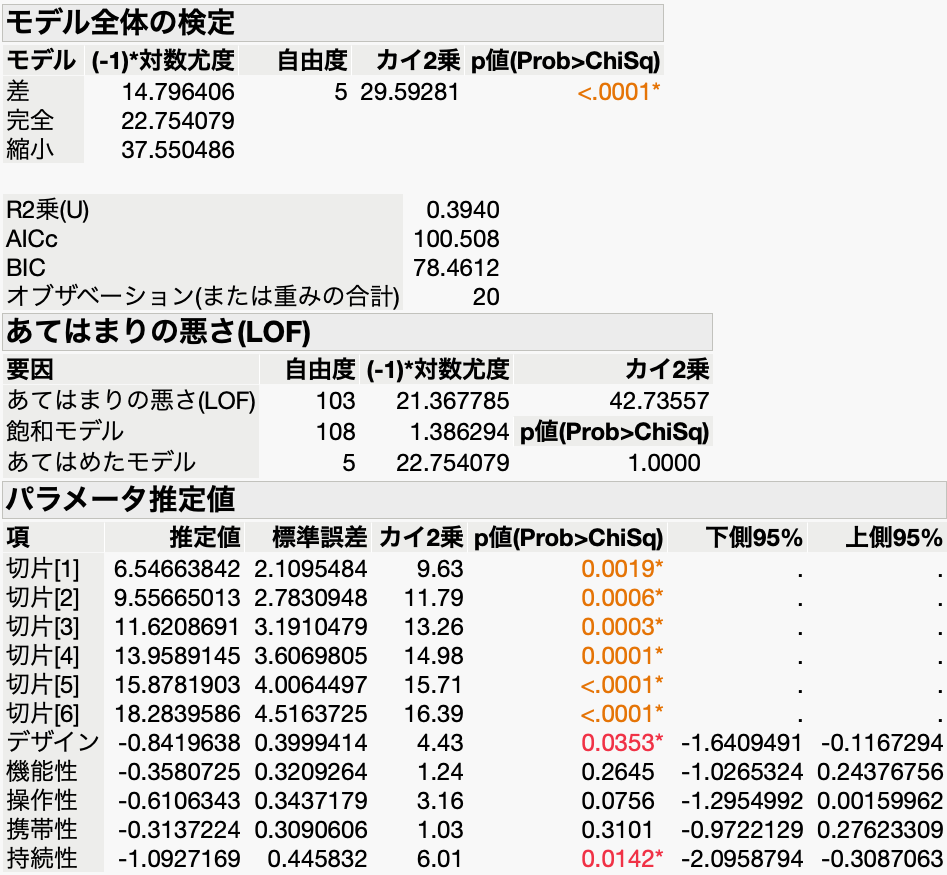
まず「モデル全体の検定」を見ると、p値が十分に小さい(<0.0001)ので、今回の回帰式が有意である、つまり目的変数を予測・説明するのに役立つと言えます。
次に「パラメータ推定値」(回帰係数の推定値)を見ると、「デザイン」と「持続性」のp値が0.05未満なので、これらが「総合評価」を説明するのに有効な説明変数ということになります。それ以外の説明変数のp値は0.05よりも大きいので、「総合評価」とは有意に関連していません。
「下限95%」「上限95%」というのは、「推定値(回帰係数)」の信頼区間のことです。信頼区間を見ると分かるように、回帰係数が有意(p値が0.05未満)というのは、95%信頼区間が0をまたがず、回帰係数が正の値か負の値のどちらかだろうということです。逆に、回帰係数の95%信頼区間が0をまたぎ、正の値をとるか負の値をとるか分からない(ゼロかもしれない)とき、有意ではないと判定されます。回帰係数がゼロなら、説明変数と目的変数の間に相関はないことになるからです。
まとめ
順序ロジスティック回帰分析は目的変数が順序尺度のときに行い、目的変数に強く関連している説明変数を見つけるための解析方法です。選択式アンケート調査の解析でよく使われますが、実はそれ以外の調査・実験データでも使えます。重回帰分析をしようと思ったけれど、目的変数の正規性や等分散性が仮定できない場合です。そんなときは、目的変数をいくつかのグループに分割して順序ロジスティック回帰分析を行うか、2つのグループに分けて二項ロジスティック回帰分析を行います。
統計解析サービス
統計解析のご依頼・ご相談に研究者が対応しています。解析方法や論文での書き方が分からないという方でも、研究者に直接相談できるのでご安心ください。料金は2万2000円〜

この記事を書いた人
田中泰章
Yasuaki Tanaka
プロフィール
自然の仕組みや環境問題、社会・教育制度などについて広い視点から考える自然科学者。2008年に東京大学大学院で博士号(環境学)を取得した後、東京大学、琉球大学、米国オハイオ州立大学、ブルネイ大学など、国内外の大学で研究と教育に約15年間携わってきました。これまでに30報以上の学術論文を筆頭著者として執筆し、国際的な科学雑誌の査読者として多数の論文審査も行っています。大学教員としては、これまでに40名以上の学生(学部・修士・博士を含む)を研究指導し、若手研究者を育成してきました。専門は「人間と自然とのかかわり」で、人間活動が自然界に与える影響を生物学・化学・社会学などの複合的な視点から研究しています。
