
KH Coderを使った計量テキスト分析:コーディングとクロス集計
複数回にわたって、KH Coderを使った計量テキスト分析について紹介しています。KH Coderは樋口耕一氏によって開発されたテキスト分析(テキストマイニング)のためのツールで、テキストの中で使用されている語を素早く集計・分析することができます。
前回の記事では、対応分析を使ってグループ間の関係を分析する方法をご紹介しました。
KH Coderを使った計量テキスト分析:対応分析でグループ間の関係を調べる
KH Coderを使ったテキスト分析(テキストマイニング)の方法をご紹介します。研究論文を書くことを目的として、グループ間の比較に重点を置きながらいくつかの記事を書い…

今回は、前回までの分析の応用編として、テキストから抽出された語をそのまま分析に使用するのではなく、指定した語や表現から「概念」を抽出し(コーディング)、その概念を使って分析する方法について解説していきます。
前回までと同様に、サンプルとして用いたテキストデータは、KH Coderにあらかじめ入っている夏目漱石の『こころ』で、データは表1のようにエクセルにまとめられています。
表1 テキストデータの配置

今回もグループ間を比較するような研究を想定して、「上」「中」「下」という3つの部に注目していきます。
コーディングとは
KH Coderにおけるコーディングとは、特定の語や表現を指定して、1つの概念としてまとめる作業です。
KH Coderの中にあらかじめ用意されている、『こころ』を分析するためのコーディングルールを掲載しておきます。
*人の死
死後 or 死病 or 死期 or 死因 or 死骸 or 生死 or 自殺 or 殉死 or 頓死 or 変死 or 亡 or 死ぬ or 亡くなる or 殺す or 亡くす or 死*恋愛
愛 or 恋 or 愛す or 愛情 or 恋人 or 愛人 or 恋愛 or 失恋 or 恋しい*友情
友達 or 友人 or 旧友 or 親友 or 朋友 or 友 or 級友*信用・不信
信用 or 信じる or 信ずる
or 不信 or 疑い or 疑惑 or 疑念 or 猜疑 or 狐疑 or 疑問 or 疑い深い or 疑う or 疑る or 警戒*病気
医者 or 病人 or 病室 or 病院 or 病症 or 病状 or 持病 or 死病 or 主治医 or 精神病 or 仮病 or 病気 or 看病 or 大病 or 病む or 病
このようにコーディングルールを作成すると、例えば「死後」「死病」「死期」などの単語は、すべて「人の死」という概念(コード)にまとめられます。このようにコードとして集計することで、複数の語や表現を1つにまとめることができるため、膨大なテキストデータの全体像を把握できるようになります。
当然ですが、テキストデータの中で使用されていない語や表現を指定しても、コードとしてカウントされません。コーディングルールを作成するときは、KH Coderの「抽出語リスト」や「関連語検索」の機能を使いながら、どのような語や表現がよく使用されているのか注意深く探っていく必要があります。抽出語リストの作成方法はこちらの記事をご覧ください。
KH Coderを使った計量テキスト分析:頻出語の抽出とグループ間の比較
KH Coderを使ったテキスト分析(テキストマイニング)の方法をご紹介します。研究論文を書くことを目的として、グループ間の比較に重点を置きながらいくつかの記事を書い…
グループとコードのクロス集計
コーディングルールを作成したら、KH Coderの「クロス集計」機能を使って、グループごとにコードの出現回数を集計します。今回のサンプルデータからは、表2のようにコードが抽出されました。
表2 コードの出現回数
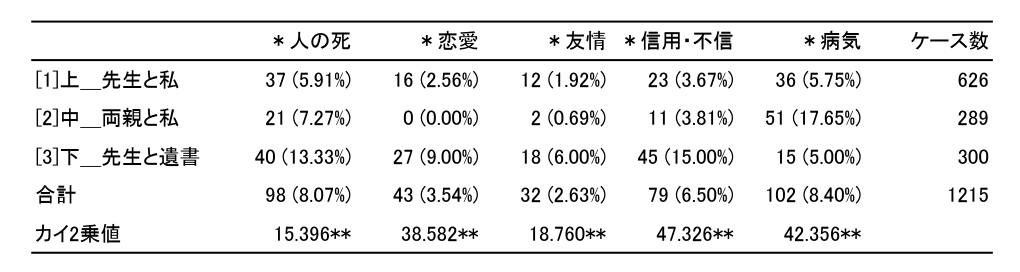
この表の見方としては、まず「上」に注目すると、「ケース数」は626とあり、626個のサンプル(集計単位)があったことが分かります。今回の集計単位はエクセルの1つのセル(KH Coderでは「H5」)としていますので、626個のセル、つまりエクセルで626行分のデータが「上」の中に含まれていたということです。そして、そのうちの37個(5.91%)のセルに「人の死」というコードが含まれていました。
同じようにして見ていくと、「中」には7.27%、「下」には13.33%のセルに「人の死」というコードが含まれていたことが分かります。これらのコードの割合が、「上」「中」「下」という3つのグループ間で有意に異なるかどうかをカイ2乗検定で分析した結果が、「カイ2乗値」に示されています。今回の場合、アスタリスク2つ(**)なので、有意水準1%(p<0.01)でコードの出現割合がグループ間で有意に異なっていたことになります(もしアスタリスクが1つであれば、p<0.05)。
ここで注意しなければならないのは、今回のように3グループ以上を比較する場合、カイ2乗検定で有意だったからといって、「『上』よりも『中』のほうが有意に高い」とか、「『中』よりも『下』のほうが有意に高い」などとは言えないということです。このカイ2乗検定で見ているのは、コードの出現割合に偏りがあるかどうかということだけで、どのグループ間に有意な差があるのかまでは分かりません。それを調べるには、グループの数を2つに限定して(例えば、「上」と「中」だけが含まれるファイルを作成して)分析する必要があります。
バブルプロットでクロス集計表を可視化する
図1は、表2のクロス集計表をバブルプロットで視覚化したものです。
.png)
図1 部(上・中・下)ごとに見たコードの出現割合(バブルプロット)
四角の大きさはコードの出現割合を、色は標準化残差を示しています。標準化残差とは、あるコードの中でそのグループがどれだけ特異かを示した数値です。例えば、「病気」というコードの中では「中」が赤く表現されており、「上」や「下」よりも多く出現していたことが分かります。
比較したいグループが多いとき
ここまで「上」「中」「下」という3つの部を比較してきましたが、文脈をさらに詳細に分析したい場合、それぞれの部の中に入っている章や節、段落などに注目することも可能です。
『こころ』のテキストデータ(表1)には全部で110の章が入っており(「上」に36章、「中」に18章、「下」に56章)、章単位で傾向を見たい場合は、KH Coderでクロス集計するときに比較対象を「章」に設定します。そうすると、最初の章から最後の章まで、110の章が縦に並んだクロス集計表が表示されます。
クロス集計表のままでは見にくいため、バブルプロットを出力してみました(図2)。
-1024x235.png)
図2 章ごとに見たコードの出現割合(バブルプロット)
横軸に章の番号、縦軸にコードが表示されています。図2から、例えば「人の死」というコードは小説の中盤と後半で多く出現し、「信用・不信」というコードは小説の中盤で多く出現していることが分かります。
変化の様子を色ではなく数値で把握したい場合は、バブルプロットではなく折れ線グラフを出力します。すべてのコードを折れ線グラフで出力すると見にくかったので、ここでは「人の死」と「信用・不信」だけを出力してみました(図3)。
.png)
図3 章ごとに見たコードの出現割合(折れ線グラフ)
バブルプロットと同様に、「人の死」は小説の中盤と後半で、「信用・不信」は小説の中盤で多く出現していることが分かります。バブルプロットと異なるのは、縦軸が数値(出現割合:%)になっているため、大小関係が把握しやすいという点です。
今回の分析例は小説の流れに沿ってコードを追跡したものですが、このような分析は時系列変化に注目した研究にも有用だと思います。例えば数十年分の新聞記事を対象にして、1年ごとにテキストデータを整理し、特定のコードが出現する頻度や割合を時系列で解析するような研究です。クロス集計の結果はエクセルに出力することができるので、エクセルを使ってコードの出現傾向を詳細に解析していくことも可能です。
まとめ
今回の記事では、コーディングとクロス集計でグループ間を比較する方法をご紹介しました。コーディングルールを作成するのは少し時間がかかるかもしれませんが、どのような語や表現を1つのコードとしてまとめるのかは、分析結果を左右する重要な過程です。コーディングルールを作成できれば、群間比較や時系列解析などさまざまな分析で利用できますので、ご自身の研究にも適用できないかぜひ検討されてみてください。
参考文献
- 樋口耕一『社会調査のための計量テキスト分析』2020年、ナカニシヤ出版
- 樋口ほか『動かして学ぶ!はじめてのテキストマイニング』2022年、ナカニシヤ出版

この記事を書いた人
田中泰章
Yasuaki Tanaka
プロフィール
自然の仕組みや環境問題、社会・教育制度などについて広い視点から考える自然科学者。2008年に東京大学大学院で博士号(環境学)を取得した後、東京大学、琉球大学、米国オハイオ州立大学、ブルネイ大学など、国内外の大学で研究と教育に約15年間携わってきました。これまでに40本以上の論文を出版し、国際的な科学雑誌の査読者として多数の論文審査も行っています。大学教員としては、これまでに40名以上の学生(学部・修士・博士)を研究指導し、若手研究者を育成してきました。専門は「人間と自然とのかかわり」で、人間活動が自然界に与える影響を生物学・化学・社会学などの複合的な視点から研究しています。
統計解析サービス
統計解析・データ分析のご依頼・ご相談に研究者が対応しています。基本統計量、グループ間の比較、相関分析、回帰分析、多変量解析など幅広く対応しておりますので、お気…
論文査読サービス
教員や研究者の論文投稿を支援するサービスです。現役の研究者が査読者目線で原稿を添削し、アドバイスを提供しています。日本語を校正・添削するプランもあります。初回…

アカデミックラウンジ
サービス案内

