
KH Coderを使った計量テキスト分析:頻出語の抽出とグループ間の比較
今回から複数回にわたって、KH Coderを使った計量テキスト分析について紹介したいと思います。KH Coderは樋口耕一氏によって開発されたテキスト分析(テキストマイニング)のためのツールで、テキストの中で使用されている語を素早く集計・分析することができます。
その使いやすさからさまざまな分野の人たちに利用されており、KH Coderの基本的な使い方についてはすでにインターネット上にも多くの記事が見られます。しかし、大部分の記事はあくまで基本的な使い方の解説にとどまっているようで、研究論文を書くための使い方としては少し物足りないかもしれません。
そこで本サイトの記事では、「研究論文を書く」という目的を想定しながら、KH Coderの使い方について解説したいと思います。
ソフトのインストール方法やテキストの前処理、頻出語の抽出など、基本的な使い方については省略すると思いますので、樋口氏の書籍や他のネット記事をご参照ください。
KH Coderを研究で上手く利用するには
樋口氏は著書『社会調査のための計量テキスト分析』(2020年、ナカニシヤ出版)の中で、KH Coderを上手く使って研究した事例を紹介していますが、分析を始める前に次の3つを明確にしておくことが大切だと指摘しています。
(1)分析から明らかにすべき問い
(2)比較の枠組み
(3)注目する概念・言葉
中でも「比較の枠組み」は重要で、次のように総括されています。
取り上げた8つの応用研究すべてにおいて、時期ごと、送り手の属性ごと、テーマごとなど、何らかの形で比較が行われており、比較の重要性は明らかである。そして各応用研究においては、何と何を比べるかという比較枠組みをたくみに設定することで、興味深い差異を発見していた。そうした比較においては、データ中のある部分で特に多く出現する言葉やコード、すなわち特徴的な語やコードを見ることが多い。それに加えて特徴的な共起を見ると、発見につながりやすいようである。
樋口耕一『社会調査のための計量テキスト分析』、2020年、ナカニシヤ出版
例えばメディア研究であれば、メディア媒体の種類(新聞・テレビ・SNSなど)を比較する、メディア会社(朝日新聞・読売新聞・毎日新聞など)を比較する、記事の年代(1990年代・2000年代・2010年代など)を比較する、などが考えられるでしょう。
アンケート調査であれば、性別や年代、国籍など、回答者の属性を比較することが考えられます。
何を比較するかは研究の目的によって変わってきますので、まずは研究の目的、つまり「(1)分析から明らかにすべき問い」を具体的に設定することが大切です。
データを配置する
今回から複数回にわたってKH Coderの記事を書いていく予定ですが、まずは最も基本となる「頻出語」について取り上げたいと思います。頻出語、つまりどの語句が何回使われているかというデータは、テキスト分析をする上で最も基本的な情報となるからです。
今回サンプルとして用いたテキストデータは、KH Coderにあらかじめ入っている夏目漱石の『こころ』です。データは表1のようにエクセルにまとめられています。
表1 テキストデータの配置

『こころ』は「上」「中」「下」という3つの部に分かれており、それぞれの部の中には複数の章があります。さらに一つの章には複数の段落があり、この1つの段落がエクセルA列の一つのセルに入っています。
このように、テキストデータだけでなく、「部」や「章」といったカテゴリーも別の列に併記されていることに注目してください。別の列にカテゴリー名を記入しておくことで、後の分析でカテゴリー間の比較を行うことができます。
これはもちろん、アンケート調査の自由記述など、他のテキストを分析する際にも同様です。アンケート調査であれば、回答者の属性(性別や年代など)をテキストとは別の列に記入しておくことで、属性間を比較する際に役立ちます。
今回の記事では(そしてこれ以降の記事でも)、特に部(上・中・下)の違いに注目して分析を進めていきたいと思います。
頻出語を比較する
表1のデータについて、KH Coderのメニューで「抽出語リスト」を選択すると、抽出語とそれぞれの出現回数が出力されます。表2の左端に、全文から抽出された上位の10語を示しました。最も多く使われた語は「先生」で595回、次に「K」で411回、という結果です。
表2 『こころ』から抽出した頻出語リスト(全文・上・中・下)
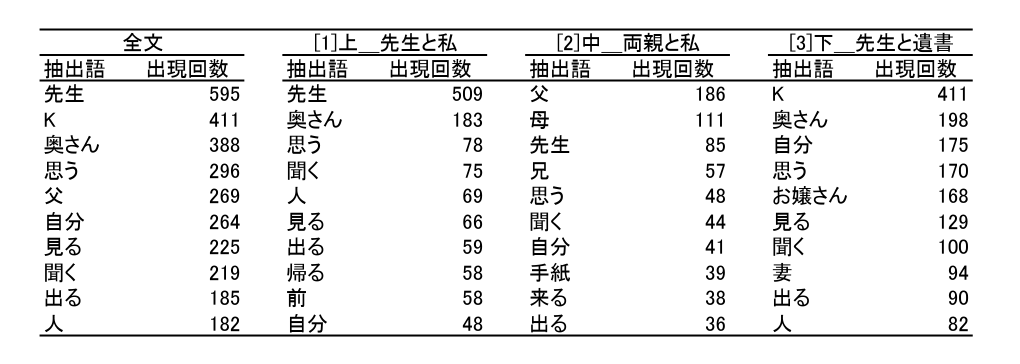
これは全文を検索した結果ですが、今回の目的である部(上・中・下)の違いを調べたいときはどうすれば良いのでしょうか。残念ながら、KH Coderにはカテゴリー別に抽出語の出現回数を出力する機能はありません。
そこで、「上」だけのファイル、「中」だけのファイル、「下」だけのファイル、というように、比較したいカテゴリーごとにファイルを作成して、別々に語句を抽出する必要があります。それを行ったのが、表2の[1][2][3]です。例えば「上」では、「先生」が最も多く509回、次に「奥さん」183回、「思う」78回、と続いています。
こうして見てみると、「上」では「先生」が、「中」では「父」「母」が、「下」では「K」が多く使われており、言い換えれば各部を特徴づける語とも言えます。
一方で、「思う」に注目すると、「上」では78回(3位)、「中」では48回(5位)、「下」では170回(4位)使用されており、どの部でも比較的多く使われている語と言えます。出現回数としては多いですが、部を特徴づけるような語とは言えないかもしれません。
このように、そのカテゴリーに特徴的な語を調べたいときは、すべてのデータが入った元のファイルを使って分析します。
カテゴリーに特徴的な語を調べる
表1のデータについて、KH Coderのメニューで「外部変数と見出し」を選択し、「変数リスト」から分類したいカテゴリーを指定します(今回の場合は「部」)。そこから出力された特徴語が表3です。
表3 各部(上・中・下)を特徴づける語
-e1768260582263.png)
表3の数値は、それぞれの語とカテゴリー(今回の場合は「部」)との関連を表すJaccardの類似性測度で、大きい順に10語表示されています。値が大きいほど(1に近いほど)、すべてのカテゴリーの中で、特にそのカテゴリーで多く出現していることを表します。
「先生」「父」「母」「K」など、出現回数(表2)の多かった語は、表3でも上位にきており、これらはその部に特徴的、つまりその部で特に多く使われていたことを示しています。
一方で、「思う」は「上」「中」では上位10語に入らず、「下」だけで4番目に入っていて、出現回数の結果とは傾向が異なります。「思う」は、回数としては「上」や「中」で多いものの、小説全体の中の分布としては「下」で多く使用されている、つまり「下」に偏っているということです。
これは言い換えれば、3つのカテゴリー(「上」「中」「下」)を比較していることになりますので、同じ手法はさまざまな比較研究で利用することができます。例えばアンケート調査であれば、回答者の属性によって使われた語がどのように異なるのかを分析したいときに利用できます。
まとめ
今回の記事では、テキストデータの中で使用されている語の頻度をグループ間で比較する方法をご紹介しました。グループごとの出現回数を出力するには、グループ別のファイルを作成しなければならない点が少し面倒ですが、出現回数は最も基本となる情報なので、ぜひ出力されてみることをおすすめします。こういった基本情報を押さえた上で、Jaccardの類似性測度のような解析を行えば(表2と表3を比較するということ)、テキストの傾向をより正確に捉えられると思います。
次回は、共起ネットワークを使ってグループ間を比較する方法についてご紹介します。
参考文献
- 樋口耕一『社会調査のための計量テキスト分析』2020年、ナカニシヤ出版
- 樋口ほか『動かして学ぶ!はじめてのテキストマイニング』2022年、ナカニシヤ出版

この記事を書いた人
田中泰章
Yasuaki Tanaka
プロフィール
自然の仕組みや環境問題、社会・教育制度などについて広い視点から考える自然科学者。2008年に東京大学大学院で博士号(環境学)を取得した後、東京大学、琉球大学、米国オハイオ州立大学、ブルネイ大学など、国内外の大学で研究と教育に約15年間携わってきました。これまでに40本以上の論文を出版し、国際的な科学雑誌の査読者として多数の論文審査も行っています。大学教員としては、これまでに40名以上の学生(学部・修士・博士)を研究指導し、若手研究者を育成してきました。専門は「人間と自然とのかかわり」で、人間活動が自然界に与える影響を生物学・化学・社会学などの複合的な視点から研究しています。
統計解析サービス
統計解析・データ分析のご依頼・ご相談に研究者が対応しています。基本統計量、グループ間の比較、相関分析、回帰分析、多変量解析など幅広く対応しておりますので、お気…

論文相談サービス
研究計画書の書き方、統計解析、論文の書き方、査読者への対応方法などについて、経験豊富な研究者に相談できます。投稿論文、科研費申請書、学振特別研究員申請書などに…

アカデミックラウンジ
サービス案内

